The exam will consist of short-answer questions, multiple choice
questions, understanding written code, and writing your own code.
The emphasis is on reading and writing code, especially with linked
lists.
If you're pushed for time, my personal recommendation is to spend
the majority of your time studying the code you wrote for your labs.
The best next thing to look at would be the materal below in the
“New Concepts” section. From there, the content in
the “C-Like Review” would be best. Overall, my
philosophy with programming is that reading and writing code are
the best ways to learn, and my questions tend to reflect this.
These questions are on old concepts which should already be familiar
to you from CS16. The majority of the points will not be on
these sort of questions, but a non-trivial number of points
will be on these questions (10-20%). Specifically, you should
be familiar with pointers and stack versus heap allocation. I say
this section is “C-Like” because it jumps between C and
C++, but the overall concepts are all endemic to C.
-
Consider the following definitions, where ... is a
placeholder for some valid initialization code:
char c = ...;
char* p = ...;
char** pp = ...;
With respect to the above definitions, what is the type of each
of the following expressions? Mark either the appropriate type,
or say “ill-typed” if it won't typecheck:
&c: char*c: char*c: ill-typed&p: char**p: char**p: char&pp: char***pp: char***pp: char*
-
Consider the following code:
int x = 7;
int* p1 = &x;
int* p2 = malloc(sizeof(int));
int* p3 = p2;
For each of the questions below, answer either “heap”
or “stack”:
- Where is
x allocated?: stack
- Where is
p1 itself allocated?: stack
- Where is what
p1 points to allocated?: stack
- Where is
p2 itself allocated?: stack
- Where is what
p2 points to allocated?: heap
- Where is
p3 itself allocated?: stack
- Where is what
p3 points to allocated?: heap
-
Name one advantage of allocating data on the stack.
Possible answers:
- Automatic deallocation
- Cheaper than allocating on the heap
-
Name one advantage of allocating data on the heap.
Possible answers:
-
Can allocate an amount of memory that can be determined
only at runtime. That is, unlike with stack allocation,
the amount allocated doesn't need to be known at compile
time.
-
Can return pointers to locally-allocated memory. That is,
the program won't automatically free space for us, which
can be advantageous.
-
Consider the following C++ code, in a file named main.cpp:
#include <iostream>
int main(int argc, char** argv) {
std::cout << argc << std::endl;
return 0;
}
Say we compile the above code like so:
clang -o args main.cpp
What is printed out by the program for each of the following
command-lines?
-
./args
1
-
./args foo
2
-
./args foo bar
3
-
Consider the following C++ code, in a file named main.cpp:
#include <iostream>
int main(int argc, char** argv) {
for(int x = 0; x < argc; x++) {
std::cout << argv[x] << std::endl;
}
return 0;
}
Say we compile the above code like so:
clang -o args main.cpp
What is printed out by the program for each of the following
command-lines?
-
./args
./args
-
./args foo
./args
foo
-
./args foo bar
./args
foo
bar
-
Name one reason why we would use a value as opposed to a pointer.
Possible answers:
- Tend to be easier to use than pointers
-
Name one reason why we would use a pointer as opposed to a value.
Possible answers:
- Allows us to avoid copying, as with function parameters
-
Allows for indirection, which is more flexible than passing
everything around by value.
-
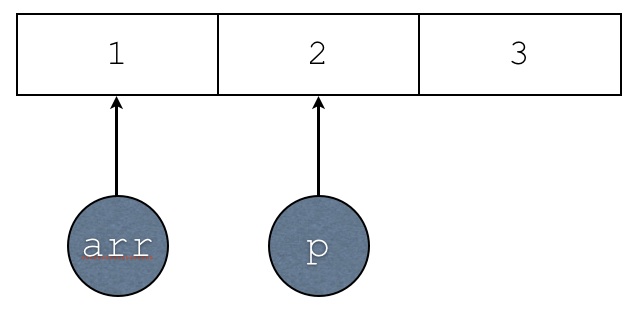
Consider the following C++ code:
int* arr = new int[3];
int* p = arr + 1;
arr[0] = 1;
arr[1] = 2;
arr[2] = 3;
Draw a diagram showing what the memory looks like after
the above code has executed.
The array, arr, and p must be
contained in the diagram for full credit.
-
The following program does not compile. Why?
int *p1 = new int[5];
void* p2 = (void*)p1;
p2[0] = 1;
Attempts to dereference a void pointer, with
the line p2[0] = 1;.
-
Why can't void pointers be dereferenced?
The compiler has no way of knowing exactly how to interpret
what is being dereferenced. For example, on most systems,
dereferencing an integer entails a slightly different operation
than dereferencing a character, since the sizes of these types
are usually different. However, with a void
pointer, all type information is lost, so the compiler can't
determine what kind of operation to use.
-
Why would someone ever use a void pointer?
Sometimes, the specific type involved in an operation or series
of operations is unimportant. For example, if we were to
define a linked list, then the operations for adding elements
wouldn't really change if we had a list of ints or
a list of char*s. In these cases, we could use
a void pointer itself and abstract over the
actual type contained within. As another example,
malloc in C returns a void pointer,
which makes sense because malloc can allocate
memory of any type.
-
What is wrong in this snippet of code? Specifically, what
is the name for this kind of bug?
int* foo() {
int x = 7;
return &x;
}
x is allocated on the stack when foo
is called. When foo returns, the space allocated
for x is deallocated. However, foo
returns a pointer to this space which will be deallocated.
As such, later attempts to dereference the returned pointer
will likely clobber someone else's memory. The returned result
called a dangling pointer, since it points to a place in
memory that it doesn't actually own.
-
What is wrong in this snippet of code? Specifically, what
is the name for this kind of bug?
void foo() {
int* x = new int;
*x = 7;
}
This code allocates space, but it never deletes it.
Moreover, since the only pointer to this space (x)
is deallocated (automatically - it's on the stack) when
foo returns, it is impossible to free up this space.
This is known as a memory leak, since it loses memory
without any way of recollecting it.
-
What is an array?
A contiguous space in memory consisting of a series
of elements of the same type. The size can be
arbitrarily large.
-
What is a struct?
A contiguous space in memory consisting of a series
of elements of possibly different types. The size of a
struct is fixed to whatever elements were
specified within.
-
The code below makes use of square brackets and the arrow
(->) operator. Rewrite it in terms of only
dereferencing (*) and pointer addition
(+).
typedef struct _foo {
int a;
char b;
} foo;
foo* arr[5];
int x;
for(x = 0; x < 5; x++) {
arr[x] = malloc(sizeof(foo));
arr[x]->a = 0;
arr[x]->b = 'b';
}
The rewritten version is below:
typedef struct _foo {
int a;
char b;
} foo;
foo* arr[5];
int x;
for(x = 0; x < 5; x++) {
*(arr + x) = malloc(sizeof(foo));
(**(arr + x)).a = 0;
(**(arr + x)).b = 'b';
}
Everything in this section is expected to be new material.
The majority of the exam will cover these sort of questions.
-
What does the logical/abstract level of an ADT define?
An interface for manipulating the ADT. It is what is used
at the application layer, and what is implemented at the
implementation layer.
-
Abstract data types (ADTs) allow us to vary the implementation
of a particular data structure without forcing application code
that uses the ADT to change. Why is this advantageous?
Because we can vary the implementation, we can easily try different
implementations which might have different characteristics about
them. For example, lists can be implemented both as arrays and
linked lists, and both offer different benefits.
-
Name one advantage of an array-based implementation of a list ADT,
as opposed to a linked-list representation.
Getting an element at a given index is cheap. For example, we can
get the last element of a list instantly with an array, whereas
with a linked list we must walk through the whole list to get
to the end. Other answers are possible.
-
Name one advantage of a linked-list implementation of a list ADT, as
opposed to an array-based representation.
Added elements to the front is cheap, and how many operations are
necessary is independent of the length of the list. In contrast,
with an array, adding elements to the front requires shifting all
elements over, which can be expensive if the array is large.
Another common benefit is that we don't need to allocate up front.
Additional answers are possible.
-
In C++, the methods below can be concurrently defined (i.e.,
all can exist without interferring with each other). Why?
What is this called?
int foo(int x);
int foo(int x, int y);
int foo(int* p);
These can all be defined because they feature different
method signatures, and C++ allows for multiple methods to
have the same name as long as their overall signatures are different.
The method signature in C++ consists of the method name, the number
of formal parameters, and the types of the formal parameters.
This is called overloading.
-
At a high-level, what does const do? Why is this
useful?
const declares something to be a runtime constant.
That is, whatever is marked const is not permitted
to change. This is useful because many bugs manifest as unintended
changes to state, and so this makes it more explicit to programmers
as to what different methods do.
-
Consider the class definition below, where the different
uses of const have been marked with the numbers
1, 2, and 3.
#include <iostream>
class Foo {
public:
// 1 2 3
void doSomething(const int* const p) const {
std::cout << *p << std::endl; // ???
*p = 8; // ???
x = p; // ???
p = NULL; // ???
std::cout << x << std::endl; // ???
}
private:
int* x;
};
There are five positions marked with ??? in
the above code. Fill in which use of const makes
the line disallowed. If the line isn't disallowed, mark it
with “ok”.
#include <iostream>
class Foo {
public:
// 1 2 3
void doSomething(const int* const p) const {
std::cout << *p << std::endl; // ok
*p = 8; // 1
x = p; // 3
p = NULL; // 2
std::cout << x << std::endl; // ok
}
private:
int* x;
};
-
Why would a programmer prefer a reference over a pointer?
References more or less allow you to refer to a data structure
directly, without using dereferencing and without using copying.
These behave much like values directly, and values are generally
nicer to work with than pointers.
-
In your own words, define each of the following object-oriented
programming (OOP) terms:
-
Object: something that typically represents a noun in the
environment, complete with a series of operations on it
and some internal state.
- Class: a template for making similar objects
- Method: an operation on an object
- Constructor: a piece of code that creates an object
-
Encapsulation: the isolation of of operations to appropriate
objects, and the isolation of object internal state from
the rest of the world. In C++, the
public
and private reserved words allow for the
encapsulation of internal state.
-
Why might the encapsulation of internal state a good thing?
It forces objects to communicate via their methods, which tends
to be much easier to reason about. If everything communicates
through a method, then all state changes can be monitored by
objects. This also prevents internal implementation details
from bleeding out to application code, meaning that application
code needs to know less about a particular implementation.
-
What is the difference between a class and an object (AKA, an
instance of a class)?
A class defines a template for making objects, whereas objects
are the output from a class.
-
Consider the code below:
class Bar {
public:
Bar(); // ???
Bar(int x); // ???
Bar(const Bar& b); // ???
int getX() const; // ???
void setX(int to); // ???
~Bar(); // ???
private:
int x; // ???
};
There are several positions in the above code which are
marked with ???. Fill in these positions with
the appropriate term which most accurrately defines
what the particular entry is. Below are the possible choices:
- Instance variable
- Method
- Method call
- Accessor method
- Mutator method
- Destructor
- Constructor
- Default constructor
- Copy constructor
- Memory allocation
The answer is below:
class Bar {
public:
Bar(); // default constructor
Bar(int x); // constructor
Bar(const Bar& b); // copy constructor
int getX() const; // accessor method
void setX(int to); // mutator method
~Bar(); // destructor
private:
int x; // instance variable
};
-
Consider the snippet of code below, where the constructors of
Baz have been labeled 1, 2,
3, and 4:
class Baz {
public:
Baz(); // 1
Baz(int x); // 2
Baz(int x, int y); // 3
Baz(const Baz& b); // 4
};
int main() {
Baz b1(10); // ???
Baz* p = new Baz(11); // ???
Baz arr[10]; // ???
Baz b2 = b1; // ???
return 0;
}
Replace ??? in the code above to reflect which
constructor is called in these different cases.
The solution is below:
class Baz {
public:
Baz(); // 1
Baz(int x); // 2
Baz(int x, int y); // 3
Baz(const Baz& b); // 4
};
int main() {
Baz b1(10); // 2
Baz* p = new Baz(11); // 2
Baz arr[10]; // 1
Baz b2 = b1; // 4
return 0;
}
-
Consider the class definition below:
class Copy {
public:
Copy() { p = new int[10]; }
Copy(const Copy& c);
~Copy() { delete[] p; }
private:
int* p;
};
Write two implementations of the copy constructor.
The first should perform a shallow copy of the provided
instance of Copy, whereas the second should
perform a deep copy.
The solution for the shallow copy is below:
Copy::Copy(const Copy& c) {
p = c.p;
}
The solution for the deep copy is below:
Copy::Copy(const Copy& c) {
p = new int[10];
for(int x = 0; x < 10; x++) {
p[x] = c.p[x];
}
}
-
Consider the code below:
#include <iostream>
using namespace std;
class Des {
public:
Des(int x) { this->x = x; cout << x << endl; }
~Des() { cout << x << endl; }
private:
int x;
};
void test() {
Des d(1);
}
int main() {
Des* p = new Des(0);
test();
delete p;
return 0;
}
If the above code is compiled and run, what is the output?
0
1
1
0
-
In one of your labs, you implemented a function in C with the
following prototype:
int compare(card* c1, card* c2);
When you implemented this in C++, the above code ended up having
a prototype similar to the one below:
int compare(Card* c);
Why aren't there two parameters in the C++ version?
This is because in C++, compare was implemented as
a method defined on the Card class. When the
compare method is called, the first card is implicitly
the Card on which the method was called. This implicit
parameter is called this. For example, in C, we
used to say:
compare(c1, c2)
...whereas in C++ we say:
c1.compare(c2)
c1 is passed to compare implicitly via
this in the C++ version.
-
Consider the class definition below:
class Simple {
public:
Simple(int x) { y = x; }
int getY() const { return y; }
void setY(int x) { y = x; }
private:
int y;
};
Rewrite the code above to explicitly use this.
class Simple {
public:
Simple(int x) { this->y = x; }
int getY() const { return this->y; }
void setY(int x) { this->y = x; }
private:
int y;
};
-
Name and describe two operations which are typical
of a stack ADT.
Possible operations:
push puts an item on top of the stackpop removes an item from the top of the stacktop observes the top element of the stack without removing it- Also will accept creating a new, empty stack
-
Name and describe two operations which are typical of a
queue ADT.
Possible operations:
enqueue adds an item to the back of the queuedequeue removes an item from the front of the queue- Will also accespt the creation of a new, empty queue
-
Consider the following code:
#include <iostream>
using namespace std;
class Stack {
public:
Stack(); // creates a new, empty stack
void push(int item); // adds an item to the stack
int pop(); // removes an item from the stack
};
class Queue {
public:
Queue(); // creates a new, empty queue
void enqueue(int item); // adds an item to the end of the queue
int dequeue(); // removes an item from the front of the queue
};
int main() {
Stack s;
Queue q;
s.push(1);
s.push(2);
s.push(3);
q.enqueue(4);
q.enqueue(5);
q.enqueue(6);
for(int x = 0; x < 3; x++) {
cout << s.pop() << " " << q.dequeue() << endl;
}
}
If the program above is compiled and run, what is the output?
3 4
2 5
1 6
-
In ??? testing, one has access to the source code.
White-box
-
In ??? testing, one does not have access to the source code.
Black-box
-
Consider a linked-list holding the elements 1,
2, and 3 in that order. Draw a memory
diagram illustrating the same list after adding 0 as
the first node and 4 as the last node. Be sure to
show the head pointer. You need only show the diagram
of the list after all the operations have occurred.
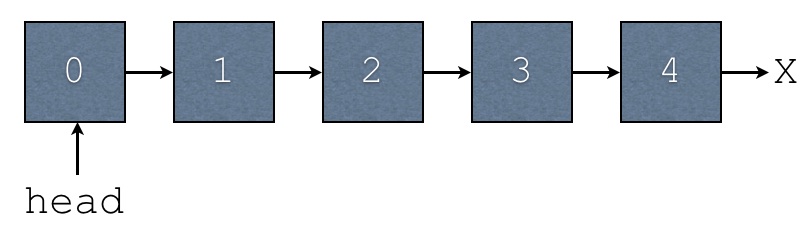
-
Consider the code below:
class Node {
public:
Node(int i) { item = i; next = NULL; }
int getItem() const { return item; }
Node* getNext() const { return next; }
void setItem(int i) { item = i; }
void setNext(Node* n) { next = n; }
private:
int item;
Node* next;
};
class List {
public:
List(); // creates a new, empty list
void addItemToFront(int item);
int getLargestItem() const;
private:
Node* head;
};
Assume that the constructor for the empty list and
addItemToFront have been implemented
elsewhere. Implement the getLargestItem
method, which should return the largest item in the list.
If the list is empty, it should return -1 (even though
this is a poor solution).
int List::getLargestItem() const {
if (head == NULL) { return -1; }
int largest = head->getItem();
for(Node* c = head->getNext(); c != NULL; c = c->getNext()) {
int item = c->getItem();
if (largest < item) {
largest = item;
}
}
return largest;
}